这座城市人很多,每天在路上都能看到好多拉着行李箱的人,不管他们是来到这座城市还是离开这座城市,至少他们都曾努力过。
Apache httpd mod_wsgi Nginx uWSGI学习笔记
以下所总结仅是学习记录,如有不对的部分,还请及时指出,十分感谢
参考文档目录较多,都在末尾列出,有兴趣的可以直接访问
Apache httpd 简介
Apache HTTPD又可以简称为httpd或者Apache,它是Internet使用最广泛的web服务器之一,使用Apache提供的web服务器是由守护进程httpd,通过http协议进行文本传输,默认使用80端口的明文传输方式,当然,后来,为了保证数据的安全和可靠性,又添加了443的加密传输的方式,Apache提供的服务器又被称为:补丁服务器,原因很简单,它是一款高度模块化的软件,想要给它添加相应的功能只需添加相应的模块,让其Apache主程序加载相应的模块,不需要的模块也可以不用加载,保证了Apache的简洁,轻便,高效性,当出现大量访问一个服务器是可以使用多种复用模式,保证了服务器能快速回应客户端的请求,如MPM,端口复用技术。
apache和httpd区别
从我们仅仅web服务器使用者的角度说的话,它们是同一个东西。在 Apache 的网站上有两种安装包下载
httpd-2.0.50-i686-pc-linux-gnu.tar.gz 和 apache_1.3.33-i686-whatever-linux22.tar.gz
其实都是提供Web服务的,只是一个是早期版一个是新的版本模式。httpd是apache开源项目的一部分,如果只需要web服务器,现在只需安装httpd2.*就可以了。
和 “Apache” 的历史有关。可以参考官方介绍:http://httpd.apache.org/ABOUT_APACHE.html
早 期的Apache小组,现在已经成为一个拥有巨大力量的Apache软件基金会,而apache现在成为 apache基金会下几十种开源项目的标识。其中有一个项目做HTTP Server,httpd是HTTP Server的守护进程,在Linux下最常用的是Apache,所以一提到httpd就会想到Apache HTTP Server。
他们把起 家的apache更名为httpd,也更符合其http server的特性。以前apache的http server在1.3的时候直接叫apache_1.3.37,现在2.*版本的都叫httpd_2.2.3。在Linux下最常用的是Apache,所 以一提到httpd就会想到Apache HTTP Server。
对于nginx/mod_wsgi,请确保阅读:
http://blog.dscpl.com.au/2009/05/blocking-requests-and-nginx-version-of.html
httpd配置相关目录
1 | [root@localhost ~]# cd /etc/httpd |
httpd配置文件
下面的三个文件分别是主配置文件和辅助配置文件,以及模块配置文件,对主配置文件进行分割方便管理,在重启服务或者重新加载配置文件时会一并加载
1 | /etc/httpd/conf/httpd.conf # 主配置文件,这个是httpd最主要的配置文档 |
模块的加载格式为:
1 | LoadModule 模块名 模块存放路径 |
模块文件目录:
1 | /usr/lib64/httpd/modules/ |
站点主服务器根目录默认:
1 | /var/www/httpd/ |
日志文件:
1 | /var/log/httpd/ |
下面是 /etc/httpd/conf/httpd.conf 简单配置的解释:
1 | # 1. ServerRoot:服务器的基础目录,一般来说它将包含conf/和logs/子目录,其它配置文件的相对路径即基于此目录。默认为安装目录,不需更改。 |
更加具体的配置文件信息可见下面的链接,作者介绍的很详细
https运行模式–MPM
MPM模块在httpd-2.4中是动态共享模块的,没有编译如主程序当中,httpd-2. 2中是静态编译入主程序当中的。在这些模型中,默认使用第一个prefork模型,第二个模型因为出错不以排查,因此使用较少,在第三个模型当中因为是比较新的功能,只有在httpd-2.4之后的版本才有的功能,所以使用较少,因为在企业使用时稳定才是王道,绝非功能越新越好
配置文件在:/etc/httpd/conf.modules.d/00-mpm.conf
1 | # Select the MPM module which should be used by uncommenting exactly |
每种模式的详解:
prefork
简介:prefork模式可以算是很古老但是非常稳定的Apache模式。Apache在启动之初,就预先fork一些子进程,然后等待请求进来。之所以这样做,是为了减少频繁创建和销毁进程的开销。每个子进程只有一个线程,在一个时间点内,只能处理一个请求。
优点:成熟稳定,兼容所有新老模块。同时,不需要担心线程安全的问题。(我们常用的mod_php,PHP的拓展不需要支持线程安全)
缺点:一个进程相对占用更多的系统资源,消耗更多的内存。而且,它并不擅长处理高并发请求,在这种场景下,它会将请求放进队列中,一直等到有可用进程,请求才会被处理。
工作原理:
一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的 (spare)或是空闲的子进程用于迎接即将到来的请求。这样客户端就无需在得到服务前等候子进程的产生。在Unix系统中,父进程通常以root身份运行以便邦定80端口,而 Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于配置子进程的低特权用户。运行子进程的用户必须要对他所服务的内容有读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。
这样可以减少频繁创建和销毁进程的开销,每个子进程只有一个线程,在一个时间点内,只能处理一个请求。这是一个成熟稳定,可以兼容新老模块,也不需要担心线程安全问题,但是一个进程相对占用资源,消耗大量内存,不擅长处理高并发的场景。
1 | -----> 派生子进程 -----> 子进程 |
配置说明:
如何配置在Apache的配置文件httpd.conf的配置方式:
1 | <IfModule mpm_prefork_module> |
- StartServers 服务器启动时建立的子进程数量,默认是5个
- MinSpareServers 空闲子进程的最小数量,默认5个;如果当前空闲子进程数少于MinSpareServers ,那么Apache将以最大每秒一个的速度产生新的子进程。此参数不要设的太大。
- MaxSpareServers 空闲子进程的最大数量,默认10;如果当前有超过MaxSpareServers数量的空闲子进程,那么父进程会杀死多余的子进程。次参数也不需要设置太大,如果你将其设置比MinSpareServers 小,Apache会自动将其修改为MinSpareServers +1的数量。
- MaxRequestWorkers 限定服务器同一时间内客户端最大接入的请求数量,默认是256;任何超过了MaxRequestWorkers限制的请求都要进入等待队列,一旦一个个连接被释放,队列中的请求才将得到服务,如果要增大这个数值,必须先增大ServerLimit。在Apache2.3.1版本之前这参数MaxRequestWorkers被称为MaxClients。
- MaxConnectionsPerChild 每个子进程在其生命周期内允许最大的请求数量,如果请求总数已经达到这个数值,子进程将会结束,如果设置为0,子进程将永远不会结束。在Apache2.3.9之前称之为MaxRequestsPerChild。
worker
简介:worker模式比起上一个,是使用了多进程和多线程的混合模式。它也预先fork了几个子进程(数量比较少),然后每个子进程创建一些线程,同时包括一个监听线程。每个请求过来,会被分配到1个线程来服务。线程比起进程会更轻量,因为线程通常会共享父进程的内存空间,因此,内存的占用会减少一些。在高并发的场景下,因为比起prefork有更多的可用线程,表现会更优秀一些。
有些人会觉得奇怪,那么这里为什么不完全使用多线程呢,还要引入多进程?
原因主要是需要考虑稳定性,如果一个线程异常挂了,会导致父进程连同其他正常的子线程都挂了(它们都是同一个进程下的)。为了防止这场异常场景出现,就不能全部使用线程,使用多个进程再加多线程,如果某个线程出现异常,受影响的只是Apache的一部分服务,而不是整个服务。
优点:占据更少的内存,高并发下表现更优秀。
缺点:必须考虑线程安全的问题,因为多个子线程是共享父进程的内存地址的。如果使用keep-alive的长连接方式,某个线程会一直被占据,也许中间几乎没有请求,需要一直等待到超时才会被释放。如果过多的线程,被这样占据,也会导致在高并发场景下的无服务线程可用。(该问题在prefork模式下,同样会发生)
注:keep-alive的长连接方式,是为了让下一次的socket通信复用之前创建的连接,从而,减少连接的创建和销毁的系统开销。保持连接,会让某个进程或者线程一直处于等待状态,即使没有数据过来。
工作原理:
和prefork模式相比,worker使用了多进程和多线程的混合模式,worker模式也同样会先预派生一些子进程,然后每个子进程创建一些线程,同时包括一个监听线程,每个请求过来会被分配到一个线程来服务。线程比起进程会更轻量,因为线程是通过共享父进程的内存空间,因此,内存的占用会减少一些,在高并发的场景下会比prefork有更多可用的线程,表现会更优秀一些;另外,如果一个线程出现了问题也会导致同一进程下的线程出现问题,如果是多个线程出现问题,也只是影响Apache的一部分,而不是全部。由于用到多进程多线程,需要考虑到线程的安全了,在使用keep-alive长连接的时候,某个线程会一直被占用,即使中间没有请求,需要等待到超时才会被释放(该问题在prefork模式下也存在)。
1 | -----> 派生子进程 -----> 线程 |
配置说明:
配置在Apache的配置文件httpd.conf的配置方式:
1 | <IfModule mpm_worker_module> |
- StartServers 服务器启动时建立的子进程数量,在workers模式下默认是3个.
- ServerLimit系统配置的最大进程数量
- MinSpareThreads空闲子进程的最小数量,默认75
- MaxSpareThreads 空闲子进程的最大数量,默认250
- ThreadsPerChild 每个子进程产生的线程数量,默认是64
- MaxRequestWorkers /MaxClients 限定服务器同一时间内客户端最大接入的请求数量.
- MaxConnectionsPerChild 每个子进程在其生命周期内允许最大的请求数量,如果请求总数已经达到这个数值,子进程将会结束,如果设置为0,子进程将永远不会结束。在Apache2.3.9之前称之为MaxRequestsPerChild。
这里建议设置为非零,注意原因:
1)能够防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2)给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量(重生的机会)。
Worker模式下所能同时处理的请求总数是由子进程总数乘以ThreadsPerChild 值决定的,应该大于等于MaxRequestWorkers。如果负载很大,现有的子进程数不能满足时,控制进程会派生新的子进程。默认最大的子进程总数是16,加大时 也需要显式声明ServerLimit(最大值是20000)。需要注意的是,如果显式声明了ServerLimit,那么它乘以 ThreadsPerChild的值必须大于等于MaxRequestWorkers,而且MaxRequestWorkers必须是ThreadsPerChild的整数倍,否则 Apache将会自动调节到一个相应值。
event
简介:这个是Apache中最新的模式,在现在版本里的已经是稳定可用的模式。它和worker模式很像,最大的区别在于,它解决了keep-alive场景下,长期被占用的线程的资源浪费问题(某些线程因为被keep-alive,空挂在哪里等待,中间几乎没有请求过来,甚至等到超时)。event MPM中,会有一个专门的线程来管理这些keep-alive类型的线程,当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放。这样增强了高并发场景下的请求处理能力。
event MPM在遇到某些不兼容的模块时,会失效,将会回退到worker模式,一个工作线程处理一个请求。官方自带的模块,全部是支持event MPM的。
注意一点,event MPM需要Linux系统(Linux 2.6+)对EPoll的支持,才能启用。
还有,需要补充的是HTTPS的连接(SSL),它的运行模式仍然是类似worker的方式,线程会被一直占用,知道连接关闭。部分比较老的资料里,说event MPM不支持SSL,那个说法是几年前的说法,现在已经支持了。
工作原理:
这是Apache最新的工作模式,它和worker模式很像,不同的是在于它解决了keep-alive长连接的时候占用线程资源被浪费的问题,在event工作模式中,会有一些专门的线程用来管理这些keep-alive类型的线程,当有真实请求过来的时候,将请求传递给服务器的线程,执行完毕后,又允许它释放。这增强了在高并发场景下的请求处理。
1 | -----> 子进程 -----> 多线程 -----> 管理&分配线程 -----> HTTP请求 |
配置说明:
配置在Apache的配置文件httpd.conf的配置方式:
1 | <IfModule mpm_event_module> |
- StartServers 服务器启动时建立的子进程数量,在workers模式下默认是3个.
- ServerLimit系统配置的最大进程数量
- MinSpareThreads空闲子进程的最小数量,默认75
- MaxSpareThreads 空闲子进程的最大数量,默认250
- ThreadsPerChild 每个子进程产生的线程数量,默认是64
- MaxRequestWorkers /MaxClients 限定服务器同一时间内客户端最大接入的请求数量.
- MaxConnectionsPerChild 每个子进程在其生命周期内允许最大的请求数量,如果请求总数已经达到这个数值,子进程将会结束,如果设置为0,子进程将永远不会结束。
ps:
1 | [root@localhost httpd]# /usr/sbin/httpd |
httpd虚拟主机的配置
基于IP地址的虚拟主机
在同一台服务器上,有多个IP地址,每一个IP地址负责一台虚拟主机的绑定,每个主机的主机名不一样如www.vhost1.com www.vhost2.com,使用较少,因为IP地址较为宝贵,而这种虚拟主机需要大量IP地址。
配置示例:
(1) 添加多个供虚拟主机使用的IP地址
1 | [root@cnode6_8conf.d]# ip a |grep 192 //此时eth2有一个IP地址 |
#使用ip命令添加三个临时IP地址
1 | [root@cnode6_8conf.d]# ip addr add 192.168.66.143/24 dev eth2 |
(2)添加虚拟主机的配置文件
1 | [root@cnode6_8conf.d]# pwd |
(3)修改/etc/hosts文件(此处不是必须的,因为这里没有DNS服务器解析域名,只好修改hosts文件以供测试!)
1 | [root@cnode6_8conf.d]# grep "^192" /etc/hosts |
(4)添加相应的目录和文件重启服务测试,添加的目录和文件都因该是配置文件定义的。这里省略这些步骤,测试结果应该为访问相应的域名,会被解析为相应的IP能访问到响应的网页
基于域名的虚拟主机
在同一台服务器上面,仅有一个IP地址,使用不同的主机名访问不同的网页内容,在虚拟主机块定义上面需要使用NameVirtualHost声明监听的IP地址,使用较多。需要注意在httpd-2.4的版本中不需要使用NameVirtualHost关键字指定监听IP地址和端口号,其余部分没有变化
(1)修改配置文件
1 | root@cnode6_8conf.d]# pwd |
(2)修改/etc/hosts文件
1 | [root@cnode6_8 conf.d]# grep 192 /etc/hosts |
(3)测试
测试时访问不同的域名,虽然是被解析为相同的IP地址,但是能访问到不同的主页
基于不同端口的虚拟主机
在同一IP,同一主机名下,使用监听不同端口,访问时需要加访问的端口。使用不多,一般用来做内网测试使用
(1)修改配置文件
1 | [root@cnode6_8conf.d]# cat virtual.conf |
(2)修改/etc/hosts文件
1 | [root@cnode6_8 conf.d]# grep 192 /etc/hosts |
测试要注意默认的端口可以不加,但是非80的端口访问时要手动添加,在访问相同的域名,不同的端口的地址时,同样可以得到不同的网页
httpd命令使用
1 | httpd -M 用来列出基于当前配置加载的所有模块 |
mod_wsgi介绍
apache mod_wsgi
在openstack中,所有提供API接口的服务都是python web server,而其本身性能很弱,目前已经将它们配置到了apache上。且加载了mod_wsgi模块
Apache HTTP服务器的mod_wsgi扩展模块,实现了Python WSGI标准,可以支持任何兼容Python WSGI标准的Python应用。
httpd中配置加载了Include conf.modules.d/?.conf和IncludeOptional conf.d/?.conf,其中
1 | Include conf.modules.d/?.conf |
1 | IncludeOptional conf.d/?.conf |
mod_wsgi.go文件放在/usr/lib64/httpd/modules/
先介绍下mod_wsgi的两种工作模式:
第一种是嵌入模式,类似于mod_python,直接在apache进程中运行,这样的好处是不需要另外增加进程,但是坏处也很明显,所有内存都和apache共享,如果和mod_python一样造成内存漏洞的话,就会危害整个apache。而且如果apache是用worker mpm,mod_wsgi也就强制进入了线程模式,这样子对于非线程安全的程序来说就没法用了。
这种模式下需要在apache的vhost中如下设置:
1 | WSGIScriptAlias /path /path-to-wsgi |
即可生效,对于小型脚本的话,直接用这种模式即可。
第二种是后台模式,类似于FastCGI的后台,mod_wsgi会借apache的外壳,另外启动一个或多个进程,然后通过socket通信和apache的进程联系。
这种方式只要使用以下配置即可:
1 | #启动WSGI后台,site1是后台名字 |
在这种模式下,我们可以通过调节processes和threads的值来设置三种MPM的模式:prefork’, ‘worker’, ‘winnt’。
1 | winnt模式 |
后台模式由于是与apache进程分离了,内存独立,而且可以独立重启,不会影响apache的进程,如果你有多个项目(django),可以选择建立多个后台或者共同使用一个后台。
比如在同一个VirtualHost里面,不同的path对应不同的django项目,可以同时使用一个Daemon:
1 | WSGIDaemonProcess default processes=1 threads=1 display-name=%{GROUP} |
这样子两个django都使用同一个WSGI后台。
也可以把不同的项目分开,分开使用不同的后台,这样开销比较大,但就不会耦合在一起了。
display-name是后台进程的名字,这样方便重启对应的进程,而不需要全部杀掉。
1 | WSGIDaemonProcess site1 processes=1 threads=1 display-name=%{GROUP} |
对于django 1.0以下的版本,由于官方认定不是线程安全的,所以建议使用多进程单线程模式
processes=n threads=1
对于django 1.0以后,就可以放心的使用多进程多线程模式:
processes=2 threads=64
这样子性能会更好。
ps:
这里介绍了关于mod_wsgi运行模式的用法:modwsgi-ProcessesAndThreading.wiki
大概总结下,运行模式分为三类:
1 | 1. prefork: |
apache-wsgi-python如何工作
客户端也就是浏览器端,当用户在浏览器的地址栏输入一个网站并且回车的时候,就会产生一个http的request请求到对应的服务器,服务器端的web服务器程序-这里就是我们的apache接受到,请求后,就查看所请求的这个url对应的虚拟机的对应的目录或者文件。这样说,可能有点晕,给个实际的例子吧:
1 | <VirtualHost 192.168.77.122:80> |
apache接受到这个请求后,发现请求对应的是目录C:/Program Files/Apache Software Foundation/Apache2.2/htdocs/test,虚拟机是myserver,这个虚拟机中有个很重要的配置是就是WSGIScriptAlias
这个东西非常关键,因为如果没有这个那么apache就不知道如何解析这个请求了。这个关键字告诉apache,该虚拟对应的目录下面的程序有wsgi对应的模块去执行,那么apache又怎么知道什么是wsgi模块,这个模块又在什么地方呢?这个需要在httpd.conf中来告诉apache,上面已经介绍过,加载mod_wsgi.go
即LoadModule wsgi_module modules/mod_wsgi.so,在httpd.conf中加入这个配置后,apache就知道wsgi是哪个模块,在什么位置了。注意LoadModule和wsgi_module是apache自己的关键字,它自己知道wsgi_module就是wsgi对应模块定义关键字。
你可以自己写一个动态库so,然后通过上面的方式-LoadModule加载进apache,但是对不起,apache并不认识你的模块,不能让你的这个so工作起来。好了我们言归正传吧,回到我们的主题。
所以当apache收到这个请求后,就知道使用mod_wsgi.so这个动态库的函数去处理请求,上面因为有这句:
WSGIScriptAlias / “C:/Program Files/Apache Software Foundation/Apache2.2/htdocs/test/mytest.py”
这样apache就知道当收到访问当前服务器的根目录时,就使用mytest.py来处理请求。谁来处理mytest.py,就是python解释器,所以mod_wsgi.so中就要创建进程-python解释器进程来解释执行mytest.py。
执行mytest.py就是为了生成这个请求的应答的内容,接着返回mod_wsgi,从而通知apache,处理完成并把结果-比如是一个html的流,apache再把这个结果发送给我们的客户端-浏览器,浏览器最后显示它。整个过程结束。
这里加一句题外话,上面是指定只要访问服务器就使用mytest.py来处理请求,这样的话,你请求别的页面,比如http://192.168.77.122/test.py那么服务器还是会使用mytest.py来处理请求,这不是我们希望的,我们希望用户访问不同的页面会有不同结果。怎么办呢?我们只要一个小小的改变就可以,就是将上面的有wsgiscriptAlias那就修改为下面的这句:
WSGIScriptAlias / “C:/Program Files/Apache Software Foundation/Apache2.2/htdocs/test”
这样就达到我们的效果了。
nginx mod_wsgi
其实nginx也可以使用mod_wsgi的模块,但是由于nginx在底层是一个事件驱动系统,因此它具有不利于阻塞应用程序的行为特征,例如基于WSGI的应用程序。更糟糕的情况是,使用多进程nginx配置,您可以看到用户请求被阻止,即使某些nginx工作进程可能处于空闲状态。Apache/mod_wsgi没有这个问题,因为Apache进程只有在有资源实际处理请求时才会接受请求。因此,Apache/mod_wsgi将提供更可预测和可靠的行为。
Nginx、WSGI、 uWSGI、 uwsgi 简介
当我们部署完一个应用程序,浏览网页时具体的过程是怎样的呢?首先我们得有一个 Web 服务器来处理 HTTP 协议的内容,Web 服务器获得客户端的请求,交给应用程序,应用程序处理完,返回给 Web 服务器,这时 Web 服务器再返回给客户端。Web 服务器与应用程序之间显然要进行交互,这时就出现了很多 Web 服务器与应用程序之间交互的规范,最早出现的是 CGI,后来又出现了改进 CGI 性能的FasgCGI,Java 专用的 Servlet 规范,Python 专用的 WSGI 规范等等。有了统一标准,程序的可移植性就大大提高了。这里我们只介绍 WSGI。
WSGI 全称是 Web Server Gateway Interface,也就是 Web 服务器网关接口,它是 Python 语言定义出来的 Web 服务器和 Web 应用程序之间的简单而通用的接口,基于现存的 CGI 标准设计,后来在很多其他语言中也出现了类似的接口。 总的来说,WSGI 可以分为服务器和应用程序两个部分,实际上可以将 WSGI 理解为服务器与应用程序之间的一座桥,桥的一边是服务器,另一边是应用程序。
按照 web 组件分类,WSGI 内部可以分为三类,web 应用程序,web 服务器,web 中间件。应用程序端的部分通过Python 语言的各种 Web 框架实现,比如 Flask,Django这些,有了框架,开发者就不需要处理 WSGI,框架会帮忙解决这些,开发者只需处理 HTTP 请求和响应,web 服务器的部分就要复杂一点,可以通过 uWSGI 实现,也可以用最常见的 Web 服务器,比如 Apache、Nginx,但这些 Web 服务器没有内置 WSGI 的实现,是通过扩展完成的。如 Apache,通过扩展模块 mod_wsgi 来支持WSGI,Nginx可以通过代理的方式,将请求封装好,交给应用服务器,比如 uWSGI。uWSGI 可以完成 WSGI 的服务端,进程管理以及对应用的调用。WSGI 中间件的部分可以这样理解:我们把 WSGI 看做桥,这个桥有两个桥墩,一个是应用程序端,另一个是服务器端,那么桥面就是 WSGI 中间件,中间件同时具备服务器、应用程序端两个角色,当然也需要同时遵守 WSGI 服务器和 WSGI 应用程序两边的限制和需要。更详细的内容可以看PEP-333 中间件的描述
Flask 依赖的 Werkzeug 就是一个 WSGI 工具包,官方文档的定义是 Werkzeug 是为 Python 设计的 HTTP和 WSGI 实用程序库。我们需要注意的是,Flask 自带的 Werkzeug 是用来开发的,并不能用于生产环境,Flask 是 Web 框架,而 Werkzeug 不是 Web框架,不是 Web 服务器,它只是一个 WSGI 工具包,它在 Flask 的作用是作为 Web 框架的底层库,它方便了我们的开发。
我们将 uwsgi 和 uWSGI 放在一起讲解。uWSGI 是一个 Web 服务器程序,WSGI,上面已经谈到,是一种协议,uwsgi 也是一种协议,uWSGI 实现了 uwsgi、WSGI、http 等协议。 uwsgi 的介绍可以看这里,uwsgi 是 uWSGI 使用的一个自有的协议,它用4个字节来定义传输数据类型描述。尽管都是协议,uwsgi 和 WSGI 并没有联系,我们需要区分这两个词。
Nginx 简介
Nginx 是高效的 Web 服务器和反向代理服务器,可以用作负载均衡(当有 n 个用户访问服务器时,可以实现分流,分担服务器的压力),与 Apache 相比,Nginx 支持高并发,可以支持百万级的 TCP 连接,十万级别的并发连接,部署简单,内存消耗少,成本低,但 Nginx 的模块没有 Apache 丰富。Nginx 支持 uWSGI 的 uwsgi 协议,因此我们可以将 Nginx 与 uWSGI 结合起来,Nginx 通过 uwsgi_pass 将动态内容交给 uWSGI 处理。
Nginx 和 uWSGI 的关系
从上面的讲解中,我们知道,uWSGI 可以起到 Web 服务器的作用,那么为什么有了 uWSGI 还需要 Nginx 呢?
最普遍的说法是 Nginx 对于处理静态文件更有优势,性能更好。其实如果是小网站,没有静态文件需要处理,只用 uWSGI 也是可以的,但加上 Nginx 这一层,优势可以很具体:
- 对于运维来说比较方便,如果服务器被某个 IP 攻击,在 Nginx 配置文件黑名单中添加这个 IP 即可,如果只用 uWSGI,那么就需要在代码中修改了。另一方面,Nginx 是身经百战的 Web 服务器了,在表现上 uWSGI 显得更专业,比如说 uWSGI 在早期版本里是不支持 https 的,可以说 Nginx 更安全。
- Nginx 的特点是能够做负载均衡和 HTTP 缓存,如果不止一台服务器,Nginx 基本就是必选项了,通过 Nginx,将资源可以分配给不同的服务器节点,只有一台服务器,也能很好地提高性能,因为 Nginx 可以通过 headers 的Expires or E-Tag,gzip 压缩等方式很好地处理静态资源,毕竟是 C 语言写的,调用的是 native 的函数,针对 I/O做了优化,对于动态资源来说,Nginx 还可以实现缓存的功能,配合 CDN 优化(这是 uWSGI 做不到的)。Nginx 支持epoll/kqueue 等高效网络库,能够很好地处理高并发短连接请求,性能比 uWSGI 不知道高到哪里去了。
- 如果服务器主机上运行了PHP,Python 等语言写的多个应用,都需要监听80端口,这时候 Nginx 就是必选项了。因为我们需要一个转发的服务。
1 | WSGI:全称是Web Server Gateway Interface,WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述web server如何与web application通信的规范。要实现WSGI协议,必须同时实现web server和web application,当前运行在WSGI协议之上的web框架有Bottle, Flask, Django。 |
Nginx 与 Apache 的异同
Nginx和Apache一样,都是一个HTTP服务器软件,功能实现上都采用模块化结构设计,都支持通用的语言接口,如PHP、Perl、Python等,同时还支持正、反向代理,虚拟主机,URL重写,压缩传输,SSL加密传输等。它们之间最大的差别是Apache处理速度很慢,且占用很多内存资源,而Nginx却恰恰相反;在功能实现上,Apache的所有模块都支持动、静态编译,而Nginx模块都是静态编译的,同时,Apache对Fcgi支持不好,而Nginx对Fcgi的支持非常的好;最重要的是,在处理连接方式上,Nginx支持epoll,而Apache却不支持;在大小上,Nginx安装包仅仅有几百K,和Nginx比起来Apache绝对是庞然大物。在了解了Nginx和Apache之间的异同点后基本知道了Nginx作为HTTP服务器的优势所在。
Nginx的优势
通过上面的简单介绍,Nginx作为HTTP服务器的优势是显而易见的,它有很多其它Web服务器无法比拟的性能和优势:
作为Web服务器,nginx处理静态文件、索引文件以及自动索引效率非常高。
作为代理服务器,Nginx可以实现无缓存的反向代理加速,提高网站运行速度。
作为负载均衡服务器,Nginx既可以在内部直接支持Rails和PHP,也可以支持HTTP代理服务器,对外进行服务。同时支持简单的容错和利用算法进行负载均衡。
在性能方面,Nginx是专门为性能优化而开发的,在实现上非常注重效率。它采用内核Poll模型,可以支持更多的并发连接,最大可以支持对50 000个并发连接数的响应,而且占用很低的内存资源。
在稳定性方面,Nginx采取了分阶段资源分配技术,使得对CPU与内存的占用率非常低。Nginx官方表示Nginx保持10 000个没有活动的连接,这些连接只占2.5M内存,因此,类似DOS这样的攻击对Nginx来说基本上是没有任何作用的。
在高可用性方面,Nginx支持热部署,启动速度特别迅速,因此可以在不间断服务的情况下,对软件版本或者配置进行升级,即使运行数月也无需重新启动,几乎可以做到7×24小时的不间断运行。
Nginx的模块与工作原理
Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(location是Nginx配置中的一个指令,用于URL匹配),而在这个location中所配置的每个指令将会启动不同的模块去完成相应的工作。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块, HTTP模块、EVENT模块和MAIL模块等属于核心模块,HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块属于基本模块,而HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块属于第三方模块,用户根据自己的需要开发的模块都属于第三方模块。正是有了这么多模块的支撑,Nginx的功能才会如此强大。
Nginx的模块从功能上分为三类,分别是:
(1) Handlers(处理器模块)。此类模块直接处理请求,并进行输出内容和修改headers信息等操作。handlers处理器模块一般只能有一个。
(2) Filters (过滤器模块)。此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
(3) Proxies (代理类模块)。就是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如fastcgi等操作交互,实现服务代理和负载均衡等功能。
下图展示了Nginx的模块下一次常规的HTTP请求和响应的过程。
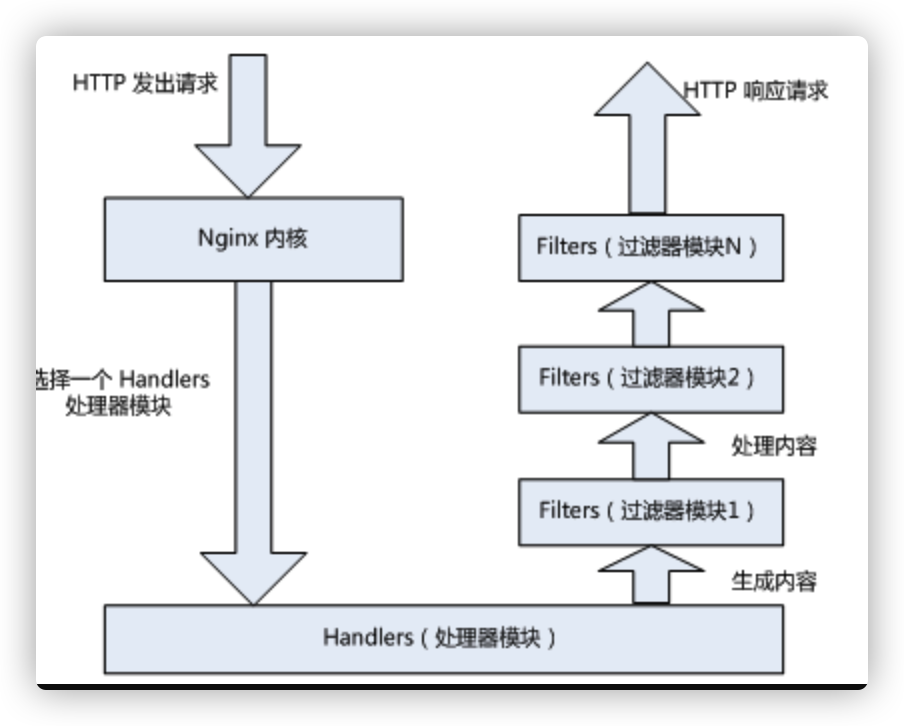
在工作方式上,Nginx分为单工作进程和多工作进程两种模式。在单工作进程模式下,除主进程外,还有一个工作进程,工作进程是单线程的;在多工作进程模式下,每个工作进程包含多个线程。Nginx默认为单工作进程模式。
Nginx的模块直接被编译进Nginx,因此属于静态编译方式。启动Nginx后,Nginx的模块被自动加载,不像在Apache一样,首先将模块编译为一个so文件,然后在配置文件中指定是否进行加载。在解析配置文件时,Nginx的每个模块都有可能去处理某个请求,但是同一个处理请求只能由一个模块来完成。
Nginx 配置文件结构
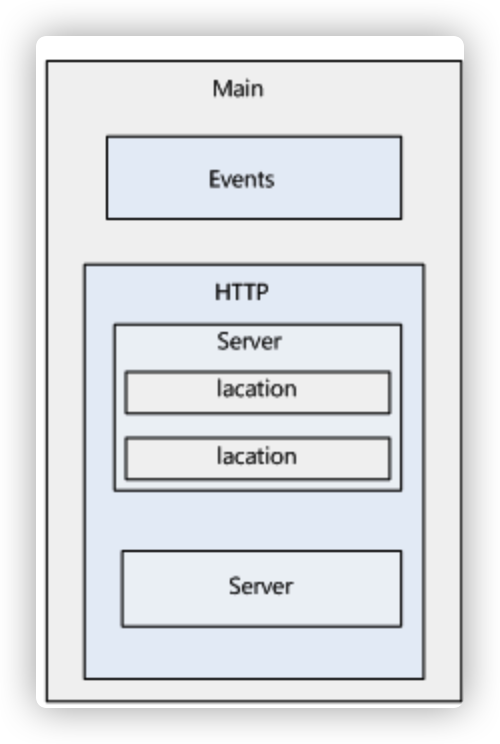
Nginx的配置文件是一个纯文本文件,它一般位于Nginx安装目录的conf目录下,整个配置文件是以block的形式组织的。每个block一般以一个大括号“{}”来表示,block可以分为几个层次,整个配置文件中Main指令位于最高层,在Main层下面可以有Events、HTTP等层级,而在HTTP层中又包含有Server层,即server block,server block中又可分为location层,并且一个server block中可以包含多个location block。
一个完整的配置文件结构如下图所示。
Nginx 配置文件详解
Nginx安装完毕后,会产生相应的安装目录,一般为/etc/nginx/conf,其中nginx.conf为Nginx的主配置文件。这里重点介绍下nginx.conf这个配置文件。
Nginx配置文件主要分成四部分:main(全局设置)、server(主机设置)、upstream(负载均衡服务器设置)和 location(URL匹配特定位置的设置)。main部分设置的指令将影响其他所有设置;server部分的指令主要用于指定主机和端口;upstream指令主要用于负载均衡,设置一系列的后端服务器;location部分用于匹配网页位置。这四者之间的关系式:server继承main,location继承server,upstream既不会继承其他设置也不会被继承。
在这四个部分当中,每个部分都包含若干指令,这些指令主要包含Nginx的主模块指令、事件模块指令、HTTP核心模块指令,同时每个部分还可以使用其他HTTP模块指令,例如Http SSL模块、HttpGzip Static模块和Http Addition模块等。
下面通过一个Nginx配置实例,详细介绍下nginx.conf每个指令的含义。为了能更清楚地了解Nginx的结构和每个配置选项的含义,这里按照功能点将Nginx配置文件分为7个部分逐次讲解,下面就围绕这7个部分进行介绍。
Nginx的全局配置
下面这段内容是对Nginx的全局属性配置,代码如下:
1 | user nobody nobody; |
对上面这段代码中每个配置选项的含义解释如下:
对上面这段代码中每个配置选项的含义解释如下:
user是个主模块指令,指定Nginx Worker进程运行用户以及用户组,默认由nobody账号运行。
worker_processes是个主模块指令,指定了Nginx要开启的进程数。每个Nginx进程平均耗费10M~12M内存。根据经验,一般指定一个进程足够了,如果是多核CPU,建议指定和CPU的数量一样的进程数即可。
error_log是个主模块指令,用来定义全局错误日志文件。日志输出级别有debug、info、notice、warn、error、crit可供选择,其中,debug输出日志最为最详细,而crit输出日志最少。
pid是个主模块指令,用来指定进程id的存储文件位置。
worker_rlimit_nofile用于指定一个nginx进程可以打开的最多文件描述符数目,这里是65535,需要使用命令“ulimit -n 65535”来设置。
events指令是设定Nginx的工作模式及连接数上限。
1
2
3
4events{
use epoll;
worker_connections 65536;
}use是个事件模块指令,用来指定Nginx的工作模式。Nginx支持的工作模式有select、poll、kqueue、epoll、rtsig和/dev/poll。其中select和poll都是标准的工作模式,kqueue和epoll是高效的工作模式,不同的是epoll用在Linux平台上,而kqueue用在BSD系统中。对于Linux系统,epoll工作模式是首选。
worker_connections也是个事件模块指令,用于定义Nginx每个进程的最大连接数,默认是1024.最大客户端连接数由worker_processes和worker_connections决定,即Max_client=worker_processesworker_connections,在作为反向代理时,max_clients变为:max_clients = worker_processes worker_connections/4。
进程的最大连接数受Linux系统进程的最大打开文件数限制,在执行操作系统命令“ulimit -n 65536”后worker_connections的设置才能生效。
HTTP服务器配置
接下来开始进行HTTP服务器设置。
下面这段内容是Nginx对HTTP服务器相关属性的配置,代码如下:
1 | http{ |
下面详细介绍下这段代码中每个配置选项的含义:
- include是个主模块指令,实现对配置文件所包含的文件的设定,可以减少主配置文件的复杂度。类似于Apache中的include方法。
- default_type属于HTTP核心模块指令,这里设定默认类型为二进制流,也就是当文件类型未定义时使用这种方式,例如在没有配置PHP环境时,Nginx是不予解析的,此时,用浏览器访问PHP文件就会出现下载窗口。
下面的代码实现对日志格式的设定。
log_format main ‘$remote_addr - $remote_user [$time_local] ‘
‘“$request” $status $bytes_sent ‘
‘“$http_referer” “$http_user_agent” ‘
‘“$gzip_ratio”‘;
log_format download ‘$remote_addr - $remote_user [$time_local] ‘
‘“$request” $status $bytes_sent ‘
‘“$http_referer” “$http_user_agent” ‘
‘“$http_range” “$sent_http_content_range”‘; - log_format是Nginx的HttpLog模块指令,用于指定Nginx日志的输出格式。main为此日志输出格式的名称,可以在下面的access_log指令中引用。
- client_max_body_size用来设置允许客户端请求的最大的单个文件字节数。
- client_header_buffer_size用于指定来自客户端请求头的headerbuffer大小。对于大多数请求,1K的缓冲区大小已经足够,如果自定义了消息头或有更大的Cookie,可以增加缓冲区大小。这里设置为32K。
- large_client_header_buffers用来指定客户端请求中较大的消息头的缓存最大数量和大小, “4”为个数,“128K”为大小,最大缓存量为4个128K。
- sendfile参数用于开启高效文件传输模式。将tcp_nopush和tcp_nodelay两个指令设置为on用于防止网络阻塞。
- keepalive_timeout设置客户端连接保持活动的超时时间。在超过这个时间之后,服务器会关闭该连接。
- client_header_timeout设置客户端请求头读取超时时间。如果超过这个时间,客户端还没有发送任何数据,Nginx将返回“Request time out(408)”错误。
- client_body_timeout设置客户端请求主体读取超时时间。如果超过这个时间,客户端还没有发送任何数据,Nginx将返回“Request time out(408)”错误,默认值是60。
- send_timeout指定响应客户端的超时时间。这个超时仅限于两个连接活动之间的时间,如果超过这个时间,客户端没有任何活动,Nginx将会关闭连接。
HttpGzip模块配置
下面配置Nginx的HttpGzip模块。这个模块支持在线实时压缩输出数据流。要查看是否安装了此模块,需要使用下面的命令:
1 | [root@localhost conf]# /etc/nginx/sbin/nginx -V |
下面是HttpGzip模块在Nginx配置中的相关属性设置:
1 | gzip on; |
- gzip用于设置开启或者关闭gzip模块,“gzip on”表示开启GZIP压缩,实时压缩输出数据流。
- gzip_min_length设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取。默认值是0,不管页面多大都进行压缩。建议设置成大于1K的字节数,小于1K可能会越压越大。
- gzip_buffers表示申请4个单位为16K的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来存储gzip压缩结果。
- gzip_http_version用于设置识别HTTP协议版本,默认是1.1,目前大部分浏览器已经支持GZIP解压,使用默认即可。
- gzip_comp_level用来指定GZIP压缩比,1 压缩比最小,处理速度最快;9 压缩比最大,传输速度快,但处理最慢,也比较消耗cpu资源。
- gzip_types用来指定压缩的类型,无论是否指定,“text/html”类型总是会被压缩的。
- gzip_vary选项可以让前端的缓存服务器缓存经过GZIP压缩的页面,例如用Squid缓存经过Nginx压缩的数据
负载均衡配置
下面设定负载均衡的服务器列表:
1 | upstream ixdba.net{ |
upstream是Nginx的HTTP Upstream模块,这个模块通过一个简单的调度算法来实现客户端IP到后端服务器的负载均衡。在上面的设定中,通过upstream指令指定了一个负载均衡器的名称ixdba.net。这个名称可以任意指定,在后面需要的地方直接调用即可。
- 在HTTP Upstream模块中,可以通过server指令指定后端服务器的IP地址和端口,同时还可以设定每个后端服务器在负载均衡调度中的状态。常用的状态有:
down,表示当前的server暂时不参与负载均衡。 - backup,预留的备份机器。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的压力最轻。
- max_fails,允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。
- fail_timeout,在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用。
- 注意 当负载调度算法为ip_hash时,后端服务器在负载均衡调度中的状态不能是weight和backup。
server虚拟主机配置
下面介绍对虚拟主机的配置。建议将对虚拟主机进行配置的内容写进另外一个文件,然后通过include指令包含进来,这样更便于维护和管理:
1 | server{ |
- server标志定义虚拟主机开始,listen用于指定虚拟主机的服务端口,server_name用来指定IP地址或者域名,多个域名之间用空格分开。Index用于设定访问的默认首页地址,root指令用于指定虚拟主机的网页根目录,这个目录可以是相对路径,也可以是绝对路径。Charset用于设置网页的默认编码格式。
- access_log logs/www.ixdba.net.access.log main;
- access_log用来指定此虚拟主机的访问日志存放路径,最后的main用于指定访问日志的输出格式。
URL匹配配置
URL地址匹配是进行Nginx配置中最灵活的部分。 location支持正则表达式匹配,也支持条件判断匹配,用户可以通过location指令实现Nginx对动、静态网页进行过滤处理。
以下这段设置是通过location指令来对网页URL进行分析处理,所有扩展名以.gif、.jpg、.jpeg、.png、.bmp、.swf结尾的静态文件都交给nginx处理,而expires用来指定静态文件的过期时间,这里是30天
1 | location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ { |
以下这段设置是将upload和html下的所有文件都交给nginx来处理,当然,upload和html目录包含在/web/wwwroot/www.ixdba.net目录中。
1 | location ~ ^/(upload|html)/ { |
在最后这段设置中,location是对此虚拟主机下动态网页的过滤处理,也就是将所有以.jsp为后缀的文件都交给本机的8080端口处理
1 | location ~ .*.jsp$ { |
StubStatus模块配置
StubStatus模块能够获取Nginx自上次启动以来的工作状态,此模块非核心模块,需要在Nginx编译安装时手工指定才能使用此功能。
以下指令实指定启用获取Nginx工作状态的功能
1 | location /NginxStatus { |
stub_status设置为“on”表示启用StubStatus的工作状态统计功能。access_log 用来指定StubStatus模块的访问日志文件。auth_basic是Nginx的一种认证机制。auth_basic_user_file用来指定认证的密码文件,由于Nginx的auth_basic认证采用的是与Apache兼容的密码文件,因此需要用Apache的htpasswd命令来生成密码文件,例如要添加一个webadmin用户,可以使用下面方式生成密码文件:
/usr/local/apache/bin/htpasswd -c /opt/nginx/conf/htpasswd webadmin
会得到以下提示信息:
New password:
输入密码之后,系统会要求再次输入密码。确认之后添加用户成功。
要查看Nginx的运行状态,可以输入http://ip/ NginxStatus,然后输入刚刚创建的用户名和密码就可以看到如下信息:
1 | Active connections: 1 |
Active connections表示当前活跃的连接数,第三行的三个数字表示 Nginx当前总共处理了393411个连接, 成功创建393411次握手, 总共处理了393799个请求。最后一行的Reading表示Nginx读取到客户端Header信息数, Writing表示Nginx返回给客户端的Header信息数,“Waiting”表示Nginx已经处理完,正在等候下一次请求指令时的驻留连接数。
在最后这段设置中,设置了虚拟主机的错误信息返回页面,通过error_page指令可以定制各种错误信息的返回页面。在默认情况下,Nginx会在主目录的html目录中查找指定的返回页面,特别需要注意的是,这些错误信息的返回页面大小一定要超过512K,否者会被ie浏览器替换为ie默认的错误页面。
1 | error_page 404 /404.html; |
Nginx 代理
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器;同时也是一个IMAP、POP3、SMTP代理服务器;Nginx可以作为一个HTTP服务器进行网站的发布处理,另外Nginx可以作为反向代理进行负载均衡的实现。
关于代理
说到代理,首先我们要明确一个概念,所谓代理就是一个代表、一个渠道;
此时就涉及到两个角色,一个是被代理角色,一个是目标角色,被代理角色通过这个代理访问目标角色完成一些任务的过程称为代理操作过程;如同生活中的专卖店~客人到adidas专卖店买了一双鞋,这个专卖店就是代理,被代理角色就是adidas厂家,目标角色就是用户。
正向代理
说反向代理之前,我们先看看正向代理,正向代理也是大家最常接触的到的代理模式,我们会从两个方面来说关于正向代理的处理模式,分别从软件方面和生活方面来解释一下什么叫正向代理。
在如今的网络环境下,我们如果由于技术需要要去访问国外的某些网站,此时你会发现位于国外的某网站我们通过浏览器是没有办法访问的,此时大家可能都会用一个代理进行访问,代理的方式主要是找到一个可以访问国外网站的代理服务器,我们将请求发送给代理服务器,代理服务器去访问国外的网站,然后将访问到的数据传递给我们!
上述这样的代理模式称为正向代理,正向代理最大的特点是客户端非常明确要访问的服务器地址;服务器只清楚请求来自哪个代理服务器,而不清楚来自哪个具体的客户端;正向代理模式屏蔽或者隐藏了真实客户端信息。
总结来说:正向代理,”它代理的是客户端”,是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
正向代理的用途:
(1)访问原来无法访问的资源,如Google
(2) 可以做缓存,加速访问资源
(3)对客户端访问授权,上网进行认证
(4)代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理
明白了什么是正向代理,我们继续看关于反向代理的处理方式,举例如我大天朝的某宝网站,每天同时连接到网站的访问人数已经爆表,单个服务器远远不能满足人民日益增长的购买欲望了,此时就出现了一个大家耳熟能详的名词:分布式部署;也就是通过部署多台服务器来解决访问人数限制的问题;某宝网站中大部分功能也是直接使用Nginx进行反向代理实现的,并且通过封装Nginx和其他的组件之后起了个高大上的名字:Tengine,有兴趣的童鞋可以访问Tengine的官网查看具体的信息:http://tengine.taobao.org/。
多个客户端给服务器发送的请求,Nginx服务器接收到之后,按照一定的规则分发给了后端的业务处理服务器进行处理了。此时~请求的来源也就是客户端是明确的,但是请求具体由哪台服务器处理的并不明确了,Nginx扮演的就是一个反向代理角色。
客户端是无感知代理的存在的,反向代理对外都是透明的,访问者并不知道自己访问的是一个代理。因为客户端不需要任何配置就可以访问。
反向代理,”它代理的是服务端”,主要用于服务器集群分布式部署的情况下,反向代理隐藏了服务器的信息。
反向代理的作用:
(1)保证内网的安全,通常将反向代理作为公网访问地址,Web服务器是内网
(2)负载均衡,通过反向代理服务器来优化网站的负载
项目场景
一般在项目中正向代理和反向代理都是同时出现的,正向代理代理客户端的请求去访问目标服务器,目标服务器是一个反向代理服务器,反向代理了多台真实的业务处理服务器:
1 | 多个客户端请求 -----> 正向代理 -----> 反向代理 -----> 多个服务器 |
在正向代理中,Proxy和Client同属于一个LAN(图中方框内),隐藏了客户端信息;
在反向代理中,Proxy和Server同属于一个LAN(图中方框内),隐藏了服务端信息;
实际上,Proxy在两种代理中做的事情都是替服务器代为收发请求和响应,不过从结构上看正好左右互换了一下,所以把后出现的那种代理方式称为反向代理了。
Nginx 负载均衡
负载均衡
我们已经明确了所谓代理服务器的概念,那么接下来,Nginx扮演了反向代理服务器的角色,它是以依据什么样的规则进行请求分发的呢?不同的项目应用场景,分发的规则是否可以控制呢?
这里提到的客户端发送的、Nginx反向代理服务器接收到的请求数量,就是我们说的负载量。
请求数量按照一定的规则进行分发到不同的服务器处理的规则,就是一种均衡规则。
所以~将服务器接收到的请求按照规则分发的过程,称为负载均衡。
负载均衡在实际项目操作过程中,有硬件负载均衡和软件负载均衡两种,硬件负载均衡也称为硬负载,如F5负载均衡,相对造价昂贵成本较高,但是数据的稳定性安全性等等有非常好的保障,如中国移动中国联通这样的公司才会选择硬负载进行操作;更多的公司考虑到成本原因,会选择使用软件负载均衡,软件负载均衡是利用现有的技术结合主机硬件实现的一种消息队列分发机制。
Nginx支持的负载均衡调度算法方式如下:
- weight轮询(默认):接收到的请求按照顺序逐一分配到不同的后端服务器,即使在使用过程中,某一台后端服务器宕机,Nginx会自动将该服务器剔除出队列,请求受理情况不会受到任何影响。 这种方式下,可以给不同的后端服务器设置一个权重值(weight),用于调整不同的服务器上请求的分配率;权重数据越大,被分配到请求的几率越大;该权重值,主要是针对实际工作环境中不同的后端服务器硬件配置进行调整的。
- ip_hash:每个请求按照发起客户端的ip的hash结果进行匹配,这样的算法下一个固定ip地址的客户端总会访问到同一个后端服务器,这也在一定程度上解决了集群部署环境下session共享的问题。
- fair:智能调整调度算法,动态的根据后端服务器的请求处理到响应的时间进行均衡分配,响应时间短处理效率高的服务器分配到请求的概率高,响应时间长处理效率低的服务器分配到的请求少;结合了前两者的优点的一种调度算法。但是需要注意的是Nginx默认不支持fair算法,如果要使用这种调度算法,请安装upstream_fair模块。
- url_hash:按照访问的url的hash结果分配请求,每个请求的url会指向后端固定的某个服务器,可以在Nginx作为静态服务器的情况下提高缓存效率。同样要注意Nginx默认不支持这种调度算法,要使用的话需要安装Nginx的hash软件包。
附录小知识
如何查看某个进程的线程数
1 | 有些时候需要确定进程内部当前运行了多少线程,查询方法如下: |
httpd process 和 wsgi process
1 | ()[root@gnocchi-api-797d4748bd-9ljfw /]# ps -ef |
为什么在apache中使用了mod_wsgi之后,却会有两个不同名字进程
根据:https://serverfault.com/questions/293595/why-are-there-double-apache-processes-for-mod-wsgi
When you use daemon mode and your Django application is therefore running in a separate process to main Apache processes, you still need the Apache parent process and at least one Apache child process. The later is what accepts requests and proxies them through to the mod_wsgi daemon processes. Read:
http://code.google.com/p/modwsgi/wiki/ProcessesAndThreading
即httpd是转发请求给wsgi进程,由wsgi进程处理具体请求
DFOREGROUND 含义
在k8s中运行的httpd和wsgi进程中总会有 DFOREGROUND
1 | ()[root@gnocchi-api-797d4748bd-9ljfw /]# ps -ef |
通俗的说就是它使得 apache 的进程一直在 console 界面的“前端”运行,而不是作为一个守护进程挂起,想象一下你用 tail -f 跟踪某个 log 文件时的窗口,就是那个效果。其目的就是让 docker “认为” apache 一直在跑着,否则 docker 就会认为自己的任务结束了,从而 exit;那是我们不希望看到的。据此,也让我对 docker 的运行机制多了一点了解。
查看apache当前并发访问数和进程数 ApacheLinux
1 | 1、查看apache当前并发访问数: |
常用web服务器对比
| 对比项 | Apache | Nginx | Lighttpd |
|---|---|---|---|
| Proxy代理 | 非常好 | 非常好 | 一般 |
| Rewriter | 好 | 非常好 | 一般 |
| Fcgi | 不好 | 好 | 非常好 |
| 热部署 | 不支持 | 支持 | 不支持 |
| 系统压力 | 很大 | 很小 | 比较小 |
| 稳定性 | 好 | 非常好 | 不好 |
| 安全性 | 好 | 一般 | 一般 |
| 静态文件处理 | 一般 | 非常好 | 好 |
| 反向代理 | 一般 | 非常好 | 一般 |
参考:
http://blog.360converter.com/archives/1005
https://www.cnblogs.com/fengchong/p/10230266.html
https://blog.csdn.net/a3192048/article/details/89737337
https://blog.51cto.com/ixdba/790611
https://blog.51cto.com/ixdba/778469
https://blog.51cto.com/ixdba/778462
https://blog.51cto.com/ixdba/793571
https://blog.51cto.com/ixdba/798913
https://blog.51cto.com/ixdba/803475
https://blog.csdn.net/weixin_34117211/article/details/85928265?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.channel_param
https://blog.csdn.net/weixin_33779515/article/details/92821188?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param
https://blog.csdn.net/weixin_33994444/article/details/92981756?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
https://blog.csdn.net/weixin_33842304/article/details/86420744?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param
https://blog.csdn.net/willierStrong/article/details/7226938?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param

